FIP-3 Memory Hard Mining Algorithm (FishHash)
description
Change the mining algorithm of Iron Fish to a memory hard POW algorithm
author
Lollidieb (@Lolliedieb), Daniel (@danield9tqh), Mat (@mat-if)
discussion
status
Final
category
Core
created
2023-12-20
Abstract
This proposes changing the Iron Fish hashing algorithm to a memory hard Proof of Work algorithm similar to Ethash. The algorithm levels the playing field between different mining hardware (ASICS, FPGAs and GPUs) to make mining more accessible to a wider range of community members.
Motivation
During the first days of the Iron Fish mainnet, it was observed that there was a high percentage of blocks of unknown origin. This unknown hashrate was unaffected by price changes compared to hashrate from GPU mining. This led the community to believe that this hash rate had a not inconsiderable economic advantage over GPU miners and that it could be coming from FPGAs or some other form of ASIC hardware.
In a voting that ended on October 3rd 2023 the mining community of Iron Fish opted to change the proof of work scheme (PoW) used in the project to a proposal made by Lolliedieb on September 18th which was eventually named FishHash. The goal behind the process was to democratizing the mining of Iron Fish. For most blockchain projects, a large number of miners in the initial mining community is beneficial because it increases the total number of people who interact with the project and increases community engagement.
The technical goal of FishHash is to be memory bandwidth bound as opposed to the current compute-bound blake3 algorithm. Memory chip hardware is all very similar in performance and characteristics, since memory cells are already extremely optimized to record data as reliably and quickly as possible. For this reason, the memory used in different device categories such as graphics cards (GPU), field programmable gate arrays (FPGA) and application-specific integrated circuit (ASIC) are all very similar and have only minor differences in their performance.
Therefore, the idea is to create a PoW scheme that is mainly based on the existence and performance of these memory chips, so that the performance and efficiency difference between specialized and widely available hardware is as small as possible. This specification describes the basic structure of this new scheme and which steps are necessary to compute a correct hash value with the new scheme.
Specification
Algorithm Outline
The basic concept of most memory-hard algorithms is based on three processing phases that will be executed in order (depicted below).
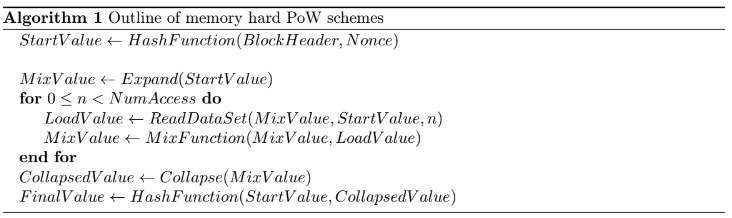
This scheme is quite commonly used by multiple PoW algorithms such as Ethash, Etchash, KawPow, Octopus or with slightly modified Autolykos just to name a few. To create a secure PoW scheme, one always relies on established hash functions for computing the initial seed and the final result. The further properties like the memory size requirement enforce a minimum device specs required to run the PoW scheme. For PoW schemes that are memory limited, which is when the central loop of operation dominates the overall run time of the algorithm, the performance that can be achieved on the algorithm is determined by the ReadDataset portion of the loop. So the total access increases with and the number of loop iterations. In order to obtain an algorithm limited by memory bandwidth, it is important that the amount of memory segments requested in the central loop is large in relation to the hash function used as well as the overhead of the mix function.
Beside memory size requirement, for many miners properties like the power draw are important. This property mostly depends on the locality of the data set, e.g. if it can be fully cached or if the device memory must be active during the mining process. It also depends on the ratio between the core dependent operations like the HashFunction and the MixFunction and the memory access call.
Hash Functions and Expanding
The hash function used for the FishHash PoW scheme is defined to be the Blake3 algorithm. We chose this algorithm because it is optimized to run on native 32 bit hardware as many GPUs are. Also its rounds are rather lightweight compared to other hash functions. Due to the IronFish block header having a size of 180 bytes the first iteration will require three rounds of Blake3, while the final hash call processing the 64 bytes of StartValue plus 32 bytes of MixValue needs to run two such iterations. The output of a Blake3 hash function call has up to 64 bytes. The MixValue used for our proof of work scheme will be 128 bytes. In order to pad the output of the initial call to this length the 64 output bytes will be duplicated. As for the final Blake3 call we will ask for a 32 Byte output of the hash function. This equals the output length the Blake3 function has when mining IronFish before the fork. Therefore the inputs and outputs of FishHash as a whole equal the usage of Blake3 function for computing the block header hash value before the fork to FishHash and the new scheme can be used as a drop in replacement.
Fetching and Mixing Values
The FishHash algorithm will always fetch three values of 128 bytes width and also aligned by 128 bytes from the data set to be processed into a new mixing value. This access size is wide enough to utilize the memory bandwidth a typical consumer GPU offers by always filling full cache lines. In order to fetch three different values of pseudo random position in every pass of the central loop, we will take different disjoint sections of the MixValue and perform a modular reduction modulo the number of items in the data set. In order to reduce the overhead we decided to use constant positions in the data set, which makes getting the reduced value easier than for example Ethash. The three positions will be offset by 32 bytes in between. This ensures that in case of multiple threads working on the same MixHash the calculation the address calculation can be spread and performed by different threads in parallel. Let for Var[a : b] denote the bytes with index a ≤ b of Var be read as an integer value of length b − a + 1 in little endian encoding. Also let DataSet[n] denote the nth 128 byte wide entry of the pre-calculated data set. Then the function ReadDataSet for FishHash is defined like follows.

For mixing the fetched data with the MixValue we decided to first modify two of the three fetched values in different manners with the existing MixValue. This ensures that the old value in its full length is relevant for the next generated iteration of MixValue. This also ensures that it is relevant if a fetched value is in first, second or third position. Afterwards we interpret the 128 bytes values as 16 integers of 64 bit or 8 bytes each and perform a single multiply and add operation on each of them to generate a new MixValue.

We define that in the description of algorithm 4 the symbol ⊕ denotes a logical bitwise xor, the function FNV is identical to the function of the same name known from the Ethash PoW, namely FNV(a, b) is defined to be (0x01000193 · a) ⊕ b. Because this function is working on 32 bit values we define this function to operate on all 32 dword sized chunks of LoadValue[128 : 255] and MixValue. Note that the two operations of the loop usually can be performed as a single multiply and add operation on most architectures, but for format reasons we decided to note them down as two separated operations.
Collapsing the Final Value
The 128 bytes output of the MixValue variable will be collapsed down to a value of length 32 bytes to reduce the computation demand of the final call to the Blake3 hash function. In order to make all bytes of MixValue important this can not happen by a simple truncation, but instead we use the same reduction function based on the above mentioned FNV function that is common to most Ethash siblings.

Data Set Generation and Parameters
Different to siblings of Ethash the data set size in FishHash is a constant value and equals 4608 MBytes or exactly 37748717 data set elements, which equals the figures for Ethash epoch 448.
The algorithm for creating the dag is almost identical to the one for creating an Ethash DAG for epoch 448, but with two central changes. First of all the seed to generate the light cache is the 32 byte value received by
Secondly the iterations used for calculating a dag item is doubled from the original value of 256 to 512. Otherwise the generation of the data set remains identical to the Ethash algorithm, because the general approach has proven itself to be free of any backdoor reducing the calculation effort over the past years.
Static Analysis: Memory Demand
As mentioned in the previous section the memory size required to mine equals 4608 MBytes. On top of this most implementations will allocate additional 72 MBytes to fit the light cache. These 72 MBytes are also required for a light verify that is exists mostly for verifying blocks, but not mining computed hashes. Note that implementation dependent these 72 MBytes are optional once the data set has been build and the space can be used for other operations afterwards. Also it is possible to keep the light cache off device and just build the dag at an lower speed in case there is shortage of memory on the device itself. With this storage requirements the algorithm can be performed on all GPUs with at least 5 GByte released during the past 6 years as well as the specialized GPUs with 5 GBytes. In case of GPUs equiped with 6 GBytes this should be feasible independent of the operating system and independently of a screen to be connected or not.
Once the minimum memory capacity requirement is met, the actual performance of the algorithm depends on the memory bandwidth of the memory. With the access width of 128 sequential and aligned bytes for each access, the memory accesses are identically wide as, for example, with the Ethash algorithm, where over 90% of the theoretically available memory bandwidth can also be used practically on all modern architectures. In each iteration of the main loop there are three such accesses. Furthermore, there are a total of 32 iterations of the main loop, so that the memory bandwidth requirement for each calculated hash value is 12288 bytes. This is 50% higher than with Ethash and it can be assumed that, unless there are other reasons to the contrary, the maximum performance of the mining process is about 2/3 of the performance of mining Ethash on the same hardware given the same settings.
Static Analysis: Computational Demand
The computational demand of calculating a single hash value is highly dependent on the actual architecture of the device the PoW scheme is supposed to be run on. For the sake of simplicity we will assume that we have an underlying architecure that is able to process one 32 bit integer or logical operation at a time. Note that the actual clock cycles used on modern architectures will be less, because most architectures offer specialized instructions that can perform multiple operations in one instruction.
For the central loop of the algorithm calculating the three addresses takes less then 10 clock cycles each. This includes the operations required to perform a Barret reduction on the 32 bit value that needs to be reduced mod the data set size and to shift it to actually generate a valid memory address from it. The application of the FNV function and the ⊕ operation on the fetched values will take 64 and 32 operations. With regard to the two 64 bit operations we can assume, that a 64 bit multiply can be emulated with five 32 bit operations on a 32 bit architecture and the 64 bit addition can be emulated with two 32 bit additions with carry over. Therefore the total amount of operations can be upper bound by 16 · (5 + 2) = 112 instructions. Overall the central loop can be estimated to take less then 32 · (30 + 64 + 32 + 112) = 7616 32-bit operations. Additionally there are the currently required three blake3 loop iterations per calculated hash. Each of them taking 12 · 8 calls to the Blake3 g-function, which consists of 14 operations with 32 bit values. Therefore the calculation of the needed Blake3 hashes will add about 3 · 7 · 8 · 14 = 2352 additional operations. Note that with this figures the computational demand is relatively small compared with the memory demand, because already the latency for fetching uncached data from the data set will span multiple hundreds of clock cycles. Also the numbers presented per hash here are significantly less then e.g. for the Ethash algorithm, because alone the 24 iterations of the twice performed keccak algorithm need to be estimated with 250 cycles for each iteration or over 12000 operations in total using the same assumptions as for our algorithm. Therefore comparing with other algorithms using a similar structure the computational demand of the algorithm is rather small and we can assume that on modern architectures the assumption to be memory bandwidth bound holds. This also applies for other device classes as FPGAs or ASICs, that should be capable of performing the algorithm once the minimum criteria of enough memory size is met, but the advantage they can gain over common hardware as GPUs is limited to improve the computational side of the algorithm, which is not performance critical. This limitation of potential performance and efficiency gains is what makes FishHash a GPU friendly algorithm in the end.
Rationale
During the voting process many other ASIC resistant algorithm were considered. Although the primary reason for choosing FishHash was the result of the votes of the mining community, there are underlying reasons why these alternatives may not be as suitable.
Ethash
Ethash was the Ethereum PoW mining algorithm before ETH switched over to PoS in Sept 2022. It was created with the goal of being a memory hard ASIC resistant algorithm and achieved that goal through much of ETH’s history. Towards the end of ETH’s PoW Bitmain and a few other ASIC companies introduced ASICs for the Ethash algorithm. Although not incredibly faster than GPUs in terms of hashrate, these ASICS were much more efficient (2-10x) in terms of power consumption. The existence of these ASICS is the main reason to not transition to Ethash as the mining algorithm.
Ethash w/ EIP 3372
EIP-3372 is an ETH Improvement Proposal that recognized the introduction of ASICS onto the ETH network and proposed a small change to Ethash in order to invalidate currently available ASICS. The change was never adopted by ETH and the network eventually transitioned to PoS. This proposal is very similar to FishHash and could be a viable alternative but was not chosen in the voting over a custom mining algorithm for Iron Fish.
Autolykos V2
Autolykos was designed for the Ergo network in 2019. It’s based on the Equihash mining algorithm (ZCash’s current algorithm). Autolykos is another memory hard hashing algorithm designed to be ASIC resistant.
Autolykos is currently viewed as successful accomplishing this ASIC resistance as there are no known ASICS on the Ergo platform. However, due to the relatively small market cap of ERG compared to ETH the incentive for ASICS has not been as prominent as for Ethash. The main reason voters did not want to go with Autolykos is most likely to not intertwine the fate of ASICS on Iron Fish ASICS on Ergo.
ProgPoW
ProgPoW is a mining algorithm originally designed for Ethereum as a replacement for Ethash. When Bitmain’s Antminer E3 for Ethash was released, it became clear that optimized hardware for Ethash existed prompting some community members to look for a replacement solution optimized for GPU miners specifically.
ProgPoW being optimized for GPUs is designed to use the entire GPU core. This means that the algorithm puts much more load on a GPU than other hashing algorithms. Because of this, ProgPoW can produce high temperatures and energy usage on GPUs. This is the main reason some mining community members did not like this approach.
EthashB3
EthashB3 is a variant of Ethash proposed by the Retheruem project. Instead of using the keccak hashing function internally it uses Blake3. The variant does change the algorithm slightly to be potentially resistant to existing Ethash ASICS but it is also possible that existing ASICS for Ethash could be re-used for EthashB3. EthashB3 has not been used for very long on an established network so it is difficult to determine the viability of existing ASICS being re-used for this algorithm.
Backwards Compatibility
Changing the hashing algorithm of Iron Fish will result in a hardfork of the chain and thus will not be backwards compatible with previous versions of the node. Individual account balances will not be affected by the change. The hardfork is addressed in FIP-10.
Security and Privacy Considerations
Cryptographic Security Concerns
The main security concerns that were considered in this proposal are
-
The new hashing algorithm could be vulnerable to known cryptographic attacks like pre-image or collision attacks.
-
The hashing algorithm still has optimizations that can be exploited by specialized hardware to gain an advatage in mining
Both of these concerns are partially mitigated by the fact that FishHash shares many similarities with Ethash. The memory cache expansion piece for example is identical. Ethash was used on Ethereum mainnet for many years and so has a certain confirmed level of security through usage. Additionally Iron Fish has commissioned an official audit of the cryptographic security of the new algorithm [TODO: Add Audit]. Supplementing this official audit many community members with a vested stake in the network have reviewed the FishHash code which is open source. This includes mining software developers, miners and mining pools.
Network Transition Concerns
Another more logistical security concern is that switching over to a new mining algorithm could result in a temporary flux in the network difficulty. If done incorrectly this could result in a temporary halt in the network. FIP-8 addresses this issue.
In addition to the potential network halt, the change in difficulty opens up re-org attack oppourtunities for bad actors. Imagine the following situation:
- FishHash activates at block 100
- 100 FishHash blocks are mined at much lower total difficulty than blake3 blocks
- The total difficulty of the longest chain is now 100b + 100f, b being the average blake3 difficulty and f being the average FishHash difficulty
- A bad actor re-mines a blake3 block 100 at a higher difficulty such that the difficulty different between block 100 and block 100' is greater than 100f. This is possible because the FishHash average difficulty is much lower than the blake3 average difficulty
- The bad actor can create a large re-org with very little hashpower
The plan to mitigate this attack is 2-fold
- Implement re-org limits (discussed further in FIP-4)
- Recommend users not send transactions during the transition period as re-orgs are still possible
Reference Implementation
The reference implementation in both Rust and C++ can be found in this github repo
Copyright
Copyright and related rights waived via CC0.